在前面的章节,你看到了多个链式集合函数的例子。比如,map和filter。这些函数会立即创建临时集合。这意味着每一步的临时结果都被保存在一个临时列表中。序列给了你一个可选的方法来完成这样的计算。这样可以避免创建一次性的临时对象。
这有一个例子:
people.map(Person::name).filter { it.startsWith("A") }
Kotlin标准库参考(文档)指出,filter和map都返回一个列表。这意味着这个链式调用将会创建两个列表:一个保存filter函数的结果,另一个存储map函数的结果。当原来的列表只有包含两个元素时,这不会有问题。但是如果你有百万个元素时,这会变得非常低效。
为了把它变得更加高效,你可以转换这个操作。请使用序列而不是直接使用集合:
people.asSequence() // 1 把初始集合转换为序列
.map(Person::name) // 2 序列支持跟集合同样的API
.filter { it.startsWith("A") } // 2
.toList() // 3 把结果序列转换为列表
应用了这个操作的结果跟之前的案例一样:一个以字母A开头的人名列表。但是在第二个例子中,没有创建保存元素的中间集合。因此,对于大量的元素,性能会有可观的改善。
在Kotlin中,集合懒操作的入口是Sequence接口。这个接口仅表示:一系列可以逐个枚举的元素。Sequence只提供了一个方法:iterator。你可以用它来从序列中获取元素值。
Sequence接口的长处在于它实现的操作。序列中的元素是延迟计算的。因此,你可以使用序列来高效的执行集合的链式操作,而无需创建集合来保存过程中的中间结果。
你可以通过调用扩展函数asSequence来把任意的集合转换为序列。为什么你需要把序列变回集合呢?如果序列那么好用,使用序列而不是集合岂不是更加方便吗?结果是:有时候是。如果你只需要遍历序列中的元素,你可以直接使用序列。如果你需要使用其他的API方法,例如,通过下标访问元素,那么你需要将序列转换为列表。
NOTE 注意 一般来说,无论何时,你在大型集合中有链式操作时,请使用序列。在8.2一节,我们将会讨论为什么在Kotlin中,常规集合的延迟操作是高效的,尽管它会创建中间的集合。但是如果集合包含大量的元素,中间的元素重拍耗时巨大,所以延迟计算更加可取。
由于序列的操作是延迟的,为了执行这些操作,你直接需要遍历序列的元素或者把它转换为集合。下一章节会解释这一点。
5.3.1 执行序列操作:中间和最终操作
序列操作分为两类:中间操作和最终操作。中间操作返回另一个序列。这个序列知道如何变换原始序列的集合。最终操作返回一个结果。这个结果可以是集合、集合元素、数字或者任意其他通过初始集合变换得到的序列(见图5.7)。
 图5.7 集合的中间操作和最终操作
图5.7 集合的中间操作和最终操作
中间操作往往是惰性的。看看这个例子,它没有最终操作:
>>> listOf(1, 2, 3, 4).asSequence()
... .map { print("map($it) "); it * it }
... .filter { print("filter($it) "); it % 2 == 0 }
运行这份代码,控制台里什么也不会打印。这意味着map和filter变换延迟了。它们当且仅当获取到结果时执行(当最终操作被调用时):
>>> listOf(1, 2, 3, 4).asSequence()
... .map { print("map($it) "); it * it }
... .filter { print("filter($it) "); it % 2 == 0 }
... .toList()
map(1) filter(1) map(2) filter(4) map(3) filter(9) map(4) filter(16)
最终操作导致所有的延迟计算都被执行了。
还有一个更重要的事要注意,在这个例子中,计算的执行顺序。原始的方法首先将会对每个元素调用map函数,然后对结果序列中的每个元素调用filter函数。这就是map和filter在集合上如何工作的。但序列并不是这样的。对于序列来说,所有的操作都会逐个应用于每个元素:处理完第一个元素(映射,然后过滤),然后处理第二个,以此类推。
这个方法意味着如果过早获取结果,某些元素根本不会被变换。我们来看一个有map和find操作的例子。首先,你把一个数映射为它的平方,之后你查找当中第一个大于3的元素:
>>> println(listOf(1, 2, 3, 4).asSequence()
.map { it * it }.find { it > 3 })
4
如果同样的操作应用于一个集合而不是序列,那么首先会计算map的结果,变换初始集合中所有的元素。第二步,在中间集合中发现一个满足预言的元素。使用序列,惰性方法意味着你可以提阿偶偶处理某些元素。图5.8解释了(使用集合)提前和延迟(使用序列)方式执行这份代码的不同点。
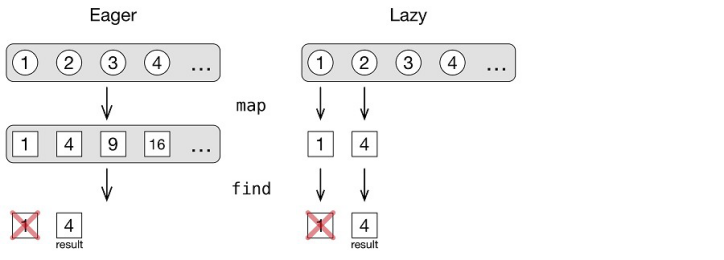 图5.8 提前计算对整个集合运行每一个操作,而惰性求值逐个计算。
图5.8 提前计算对整个集合运行每一个操作,而惰性求值逐个计算。
在第一个案例中,当你使用集合时,那个列表变换为另一个列表。所以,map变换应用于每一个元素,包括3和4。之后,找到了第一个元素满足预言的元素:2的平方。
在第二个案例中,find()调用开始逐个处理元素。你从原始序列中去除一个数字,使用map对它进行变换。然后检查它是否满足传递给find的预言。你不需要看3和4了,因为在你到达它们之前,结果已经找到了。
你对集合执行的操作顺序也会影响性能。想象一下,你有一个人的集合。你想打印它们的名字,如果它们小于某个值。你需要做两件事:把每个人映射到他们的名字,然后过滤出那些不够短的名字。在这种情形之下,你可以按任意顺序应用map和filter操作。两种方法都给出了同样的答案,但是它们需要执行的变换次数不同(见图5.9):
>>> val people = listOf(Person("Alice", 29), Person("Bob", 31),
... Person("Charles", 31), Person("Dan", 21))
>>> println(people.asSequence().map(Person::name) // 1 先执行"map",然后执行“filter”
... .filter { it.length < 4 }.toList())
[Bob, Dan]
>>> println(people.asSequence().filter { it.name.length < 4 }
... .map(Person::name).toList()) // 2 先执行“filter”,然后执行“map”
[Bob, Dan]
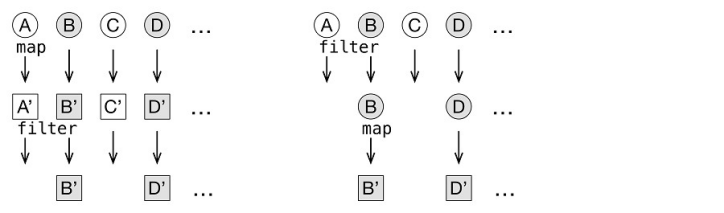 图5.9 先应用filter有助于减少变换的总次数
图5.9 先应用filter有助于减少变换的总次数
如果先进行map,每个元素都会进行变换。但是如果你先进行filter,不合适的元素会尽快过滤掉,而且不会进行变换。
SIDEBAR 流 vs 序列 如果你熟悉Java 8的流,你将会看到,(Kotlin的)序列是完全一样的概念。由于Java 8的流在使用旧版本的Java搭建的平台中不无法使用,比如Android,所以Kotlin提供了它自己的轮子。如果你把Java 8作为目标平台,流会给你带来一个很大的特性。而Kotlin的集合与序列并未实现:在多个CPU上并行执行流操作(
map()或者filter())的能力。你可以基于你面向的Java版本和你的具体要求来选择流和序列。
5.3.2 创建序列
前面的一个例子使用了同样的方法来创建一个序列:你对集合调用asSequence()。另一个可能是使用generateSequence()函数。这个函数计算序列中的前一个元素给定的下一个元素。举个例子,这是你可以如何使用generateSequence()来计算100以内所有自然数的和:
>>> val naturalNumbers = generateSequence(0) { it + 1 }
>>> val numbersTo100 = naturalNumbers.takeWhile { it <= 100 }
>>> println(numbersTo100.sum()) // 获取到"sum"结果时,执行所有的延迟操作
5050
注意,在这个例子中,naturalNumbers和numbersTo100都是带有延迟计算的序列。直到你调用最终操作时(在这个例子中是sum),这些序列中的实数才会进行计算。
另一个常见的情形是序列的父类。如果一个元素拥有它的父类(比如人类或者Java文件),也许你会对许多序列的所有祖先感兴趣。在下面的例子中,你通过生成父目录的序列并检查每个目录的熟悉来查询文件是否位于隐藏目录。
fun File.isInsideHiddenDirectory() =
generateSequence(this) { it.parentFile }.any { it.isHidden }
>>> val file = File("/Users/svtk/.HiddenDir/a.txt")
>>> println(file.isInsideHiddenDirectory())
true
你又一次通过提供第一个元素和获取每一个子序列元素的方式来创建一个序列。通过用find替换any,你将会得到想找的目录。注意,使用序列允许你一旦找到你需要的目录就停止遍历父目录。
我们已经详细讨论过lambda表达式的一个常见用途:使用它们来简化集合操作。现在,让我们继续下一个重要的话题:和现有的Java API一起使用lambda。